Motivation
In my last post where I scraped reviews for Crocs Clogs, I mentioned that I often find myself wishing for a succinct summary of the reviews for a product. Let’s flesh that out a bit more. What I mean when I say “succinct summary” is that I want a quick understanding of a specific aspect for a given product. For example, I know that crocs come in amazing colors already. I can see that in the photos. But, how do they fit? What about their comfort? I find myself often most concerned with a specific aspect of a product such as those. I want to know what people are typically saying about fit and comfort. Many retailers offer a search bar for reviews, so you can filter reviews on a keyword. BUT, searching for “fit” across all crocs reviews would return a ton of samples, and how can we know which ones are representative of the general sentiment people have in regards to fit? What if we could give consumers a snapshot of the reviews containing a word or phrase they search for? Could we show them a small set of reviews that best represent all the reviews that mention the word “fit”, for example? I think we can!
How to Make it Happen
Did someone say centroid-based clustering??? Because they would be correct. For this project we will be using the most popular centroid-based clustering algorithm, k-means.
According to Wikipedia - k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean (cluster centers or cluster centroid), serving as a prototype of the cluster.
In other words, k-means searches for the best representation of each cluster (the center) and assigns samples to a cluster based on their distance from each cluster center. So, we can say that a cluster’s center is an approximation of all the cluster’s members. Following this line of thinking, if we fit a k-means model to some data and only ask it to find 1 cluster, the calculated cluster center will act as a prototype for all the data that was passed to the model. To find the most representative subset of reviews for a particular keyword, we can filter the reviews based on the keyword, find a cluster center for the remaining samples, and get the X closest samples to the center. The closest samples to the center will be the most representative of the population. If this isn’t clear, check out the GIF below and imagine we’re only trying to make one cluster. Think about how the cluster center / centroid would move in that scenario.
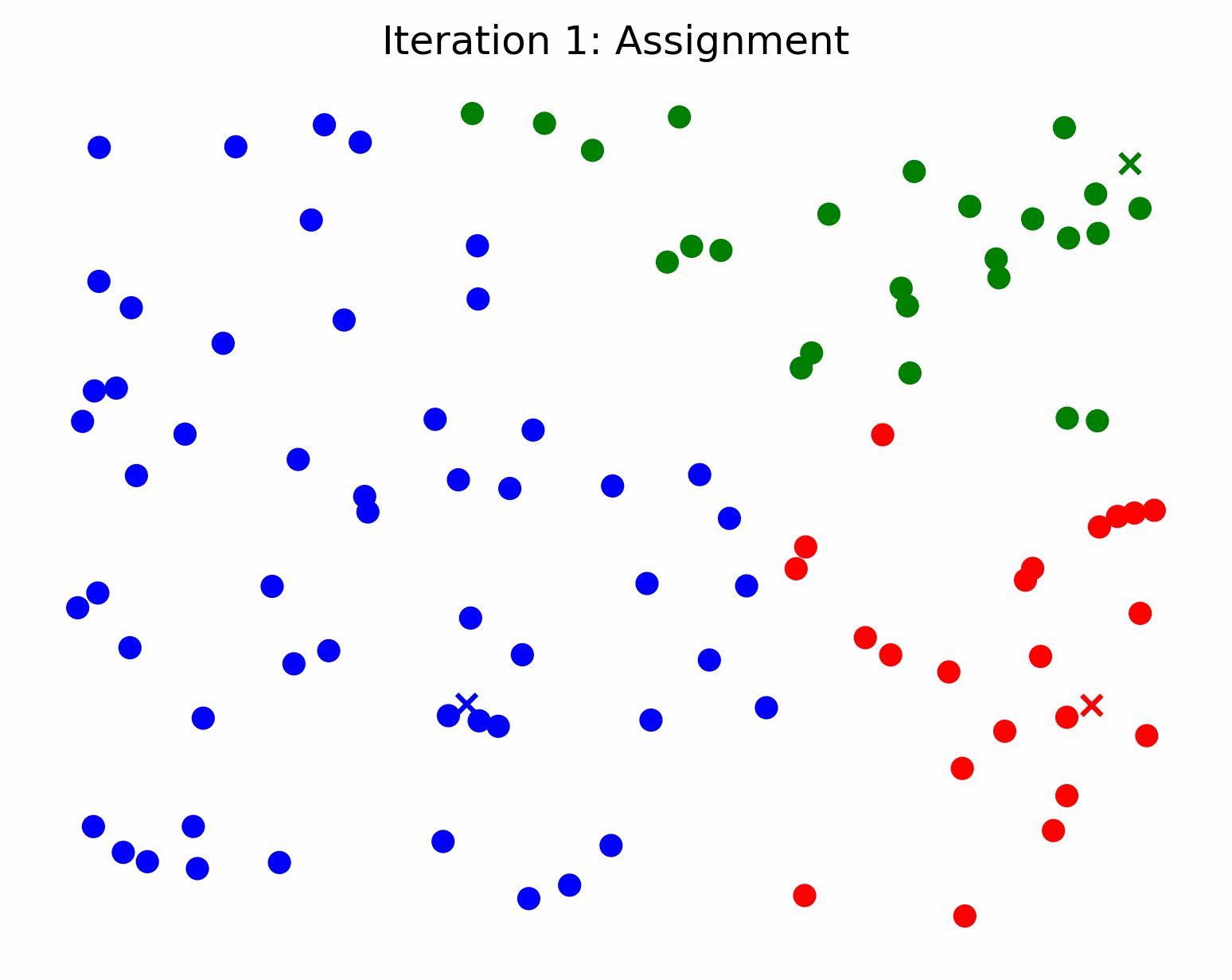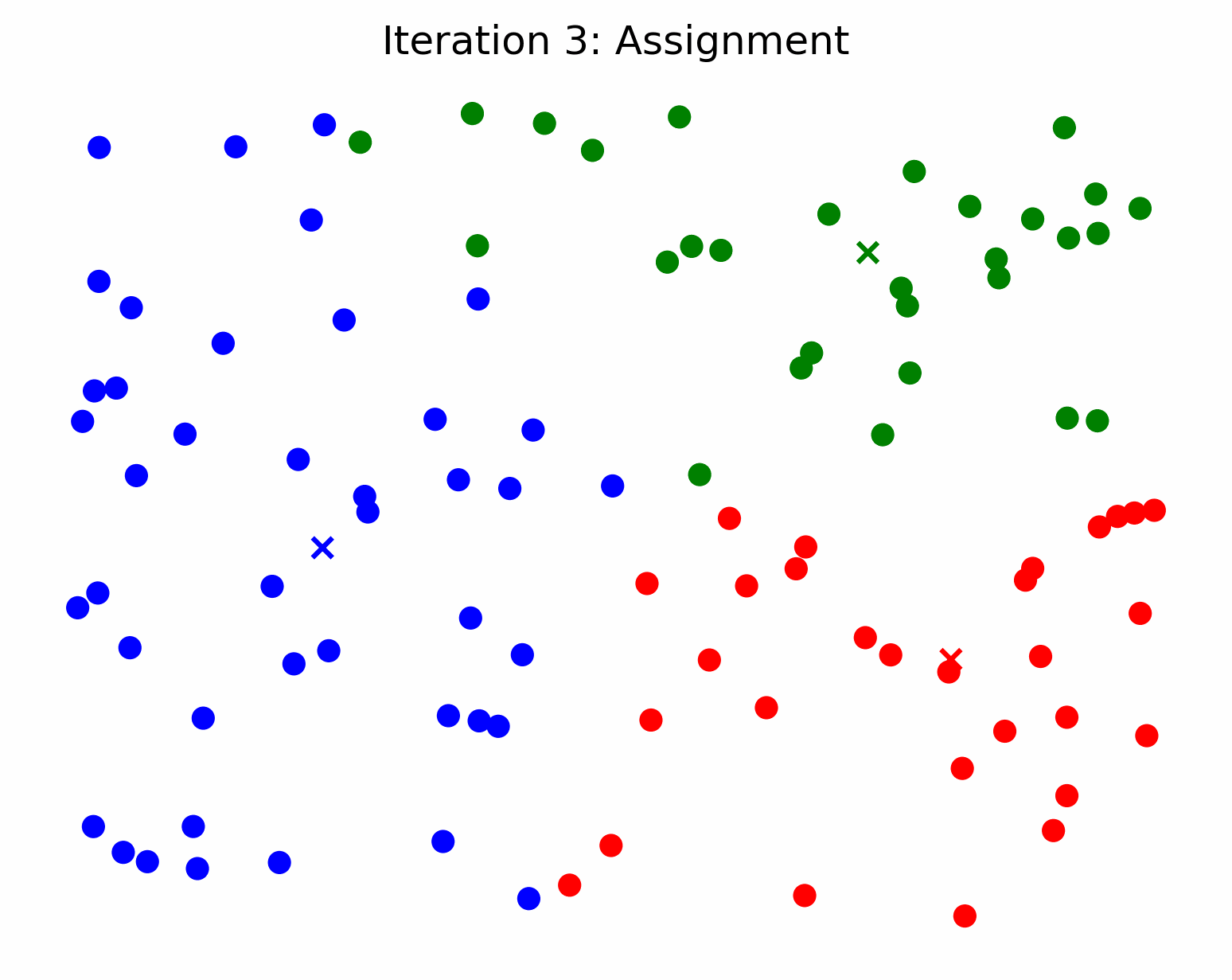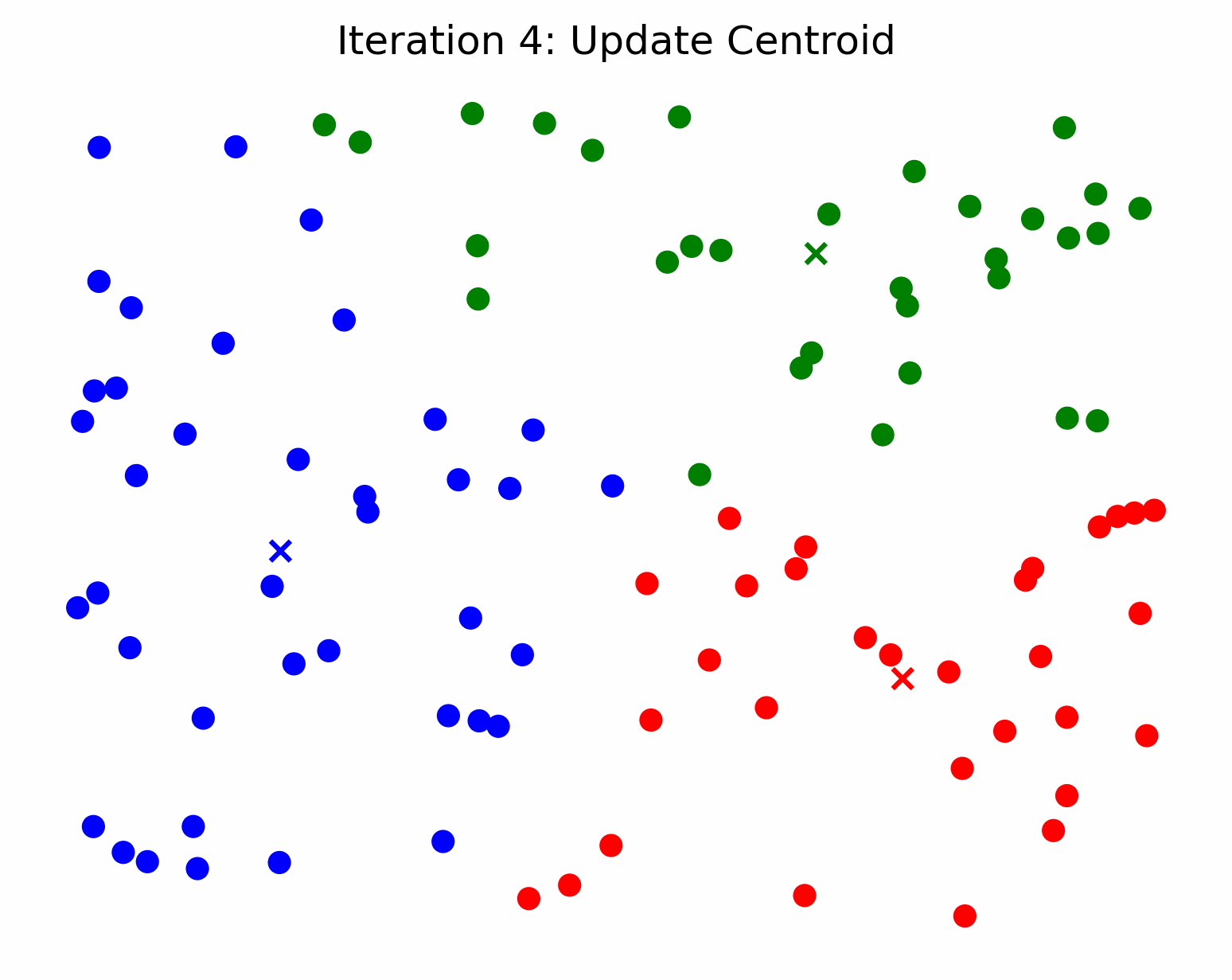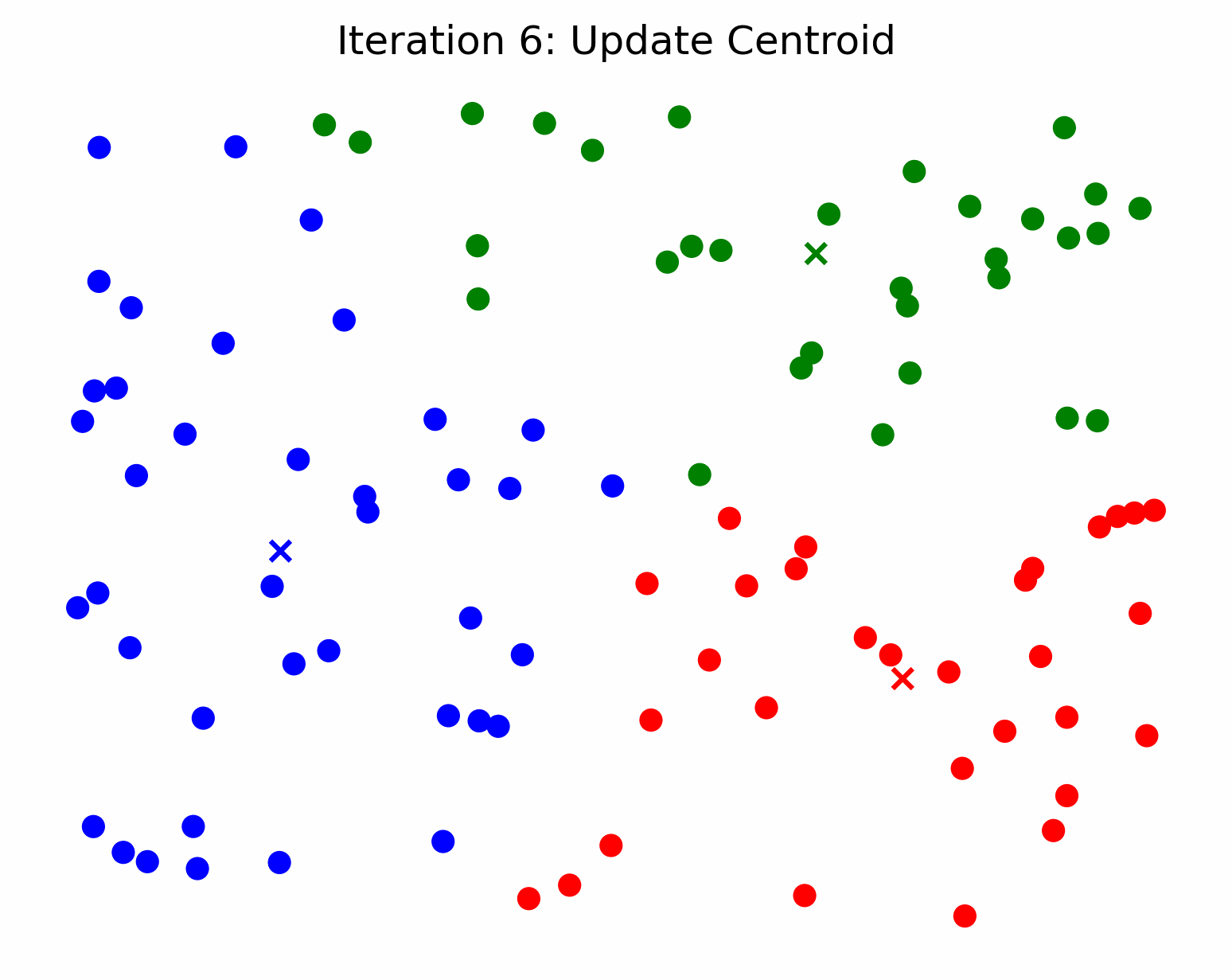 Credit - Sebastian Charmot, https://towardsdatascience.com/clear-and-visual-explanation-of-the-k-means-algorithm-applied-to-image-compression-b7fdc547e410
Credit - Sebastian Charmot, https://towardsdatascience.com/clear-and-visual-explanation-of-the-k-means-algorithm-applied-to-image-compression-b7fdc547e410
Tools Needed
Of course we will need Pandas to make for easy data manipulation and usage. We also will need to clean up our text data, so we’ll use NLTK. Finally, we need a way to vectorize the text and fit a k-means model to it, so we’ll use Scikit-Learn for that part.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
import re
import string
Clean Review Data
It’s usually very important that we stem, remove punctuation, convert to lowercase, and remove stopwords from the text we’re fitting a model on. We don’t want “Oranges” and “orange” to be treated as different words, nor do we need words like “the” and “to”, for example.
def clean_text(text):
# Remove punctuation
text = re.sub(f"[{re.escape(string.punctuation)}]", "", text)
# Convert to lowercase
text = text.lower()
# Remove stopwords
nltk.download('stopwords', quiet=True)
stop_words = set(stopwords.words('english'))
tokens = nltk.word_tokenize(text)
tokens = [word for word in tokens if word.lower() not in stop_words]
# Stemming
stemmer = PorterStemmer()
tokens = [stemmer.stem(word) for word in tokens]
# Join the tokens back into a single string
cleaned_text = ' '.join(tokens)
return cleaned_text
df = pd.read_csv('data\croc_reviews.csv')
df['clean_review'] = [clean_text(text_to_clean) for text_to_clean in df['review']]
df
| review | date | rating | clean_review | |
|---|---|---|---|---|
| 0 | !!!!!! E X C E L L E N T!!!!!!!!!! | April 7, 2022 | 5.0 | e x c e l l e n |
| 1 | "They're crocs; people know what crocs are." | April 3, 2021 | 5.0 | theyr croc peopl know croc |
| 2 | - Quick delivery and the product arrived when ... | March 19, 2023 | 5.0 | quick deliveri product arriv compani said woul... |
| 3 | ...amazing "new" color!! who knew?? love - lov... | July 17, 2022 | 5.0 | amaz new color knew love love love |
| 4 | 0 complaints from me; this is the 8th pair of ... | June 4, 2021 | 5.0 | 0 complaint 8th pair croc ive bought like two ... |
| ... | ... | ... | ... | ... |
| 9233 | I will definitely be buying again in many colo... | August 25, 2021 | 4.0 | definit buy mani color reason 45 materi feel t... |
| 9234 | I wish I would have bought crocs a long time ago. | April 8, 2021 | 5.0 | wish would bought croc long time ago |
| 9235 | wonderful. Gorgeous blue; prettier in person! | April 27, 2022 | 5.0 | wonder gorgeou blue prettier person |
| 9236 | Wonerful. Very comfy, and there are no blister... | April 8, 2021 | 5.0 | woner comfi blister feet unlik brand one |
| 9237 | Work from home - high arch need good support a... | May 22, 2023 | 5.0 | work home high arch need good support comfort ... |
9238 rows × 4 columns
Some Notes on Vectorization Methods
Since it’s been decided we’re using k-means for this project, we’re going to try out two vectorization methods and compare their performance. For each of our vectorization methods, we’ll also compute an example of their output using the two phrases “going to the store to buy bananas” and “we buy bananas” here. The vectorizers are the following:
- TF-IDF - term frequency-inverse document frequency helps by giving us an understanding of how important a word is within a document relative to an entire corpus. It is calculated by multiplying a word’s term frequency (TF) with its inverse document frequency (IDF).
TF = # of times word appears in a document / total # of terms in document
IDF = log(# of documents in corpus / # of documents in corpus that contain term)
TF-IDF = Tf X IDF
| Sample | bananas | buy | going | store | the | to | we |
|---|---|---|---|---|---|---|---|
| “going to the store to buy bananas” | 0.25 | 0.25 | 0.35 | 0.35 | 0.35 | 0.71 | 0.0 |
| “we buy bananas” | 0.50 | 0.50 | 0.0 | 0.0 | 0.0 | 0.0 | 0.70 |
- CountVectorizer - Count vectorization converts a collection of text documents into a matrix of token counts. Every word in the corpus gets its own column, so every document is converted into a vector containing the frequency of its words.
| Sample | bananas | buy | going | store | the | to | we |
|---|---|---|---|---|---|---|---|
| “going to the store to buy bananas” | 1 | 1 | 1 | 1 | 1 | 2 | 0 |
| “we buy bananas” | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
Finding Typical Reviews
The workflow for finding the most typical reviews will be:
- Filter reviews on a keyword and rating (either positive or negative)
- Vectorize the reviews with TF-IDF or CountVectorizer
- Fit a single k-means cluster
- Calculate the distance of each sample to the center of the cluster and sort
def get_tfidf(text):
vectorizer = TfidfVectorizer()
# Fit and transform review data
X = vectorizer.fit_transform(text)
return X
def get_countvect(text):
vectorizer = CountVectorizer()
# Fit and transform review data
X = vectorizer.fit_transform(text)
return X
def kmeans_distance(df, vect):
# Vectorize reviews using TF-IDF
if vect == 'tfidf':
X = get_tfidf(df['clean_review'])
# Vectorize reviews using CountVectorizer
elif vect == 'count':
X = get_countvect(df['clean_review'])
else:
print("Provide a vectorization method")
# Fit one cluster on the data.
kmeans = KMeans(n_clusters=1, random_state=0, n_init=100).fit(X)
# Compute the distance for each sample to the center of the cluster
distances = kmeans.transform(X)**2
return distances
def find_most_typical(df, word, rating, vect, asc = True):
# Let's consider anything 4 stars and up a positive review
if rating == 'positive':
df = df[df['rating'] >= 4]
else:
df = df[df['rating'] < 4]
# Clean word so it matches root word in cleaned reviews
filter_word = ' ' + clean_text(word) + ' '
#Filter using clean word
df = df[df['clean_review'].str.contains(filter_word, regex = True)]
# Retrieve review distance to center of kmeans cluster
df['distance_to_center'] = kmeans_distance(df, vect)
print("There are", len(df), rating, "reviews that mention:", word)
if asc == True:
print("The most typical reviews are:")
else:
print("The most atypical reviews are:")
for each in df.sort_values(by = 'distance_to_center', ascending = asc)['review'].tolist()[:3]:
print('# ', each)
Pseudo-evaluation
We don’t really have a way to evaluate this model, so we’re going to have to use some intuition! Firstly, let’s look at what the 3 most typical positive reviews that mention “crocs” using TF-IDF and CountVectorizer would say.
find_most_typical(df, 'crocs', 'positive', 'tfidf')
There are 2268 positive reviews that mention: crocs
Most typical reviews are:
# I love to wear these crocs because they are so comfortable.
# I love wearing my crocs. They are so comfortable.
# I love my pair of Crocs. They are so comfortable!
find_most_typical(df, 'crocs', 'positive', 'count')
There are 2268 positive reviews that mention: crocs
Most typical reviews are:
# I own a few pairs of crocs and love them all.
# I love my Crocs; they are so comfortable.
# I love Crocs; they are so comfortable!
To make sure we’re on the right track, what do the most atypical positive reviews for crocs say? We can find the samples that are farthest from the center by sorting their distance greatest to smallest.
find_most_typical(df, 'crocs', 'positive', 'tfidf', asc = False)
There are 2268 positive reviews that mention: crocs
Most atypical reviews are:
# Lids adore their Crocs! Fun with swapping charms and accessoryizing.
# Purr Nickis Impact Crocs. Ima need you to give my girl a ha check!!!!
# You can turn any none-croc person into a croc lover.
find_most_typical(df, 'crocs', 'positive', 'count', asc = False)
There are 2268 positive reviews that mention: crocs
Most atypical reviews are:
# Do you really need one more Croc review to convince you to buy these shoes? Never in a kabillion years did I think I'd ever buy a pair of Crocs. Nope, not my style, not my vibe, and not me, ever. But the husband had plantar fasciitis in one of his feet, and the pain was incredible. There are several options for shoes, but we're on a budget, and I kept reading about Crocs as a good starting point. So I ordered him some Crocs in the olive green. Then I thought, "My husband is a big baby. I should order myself a pair, wear them around for a day, and rave about them so he'll immediately start wearing his own pair of Crocs and start healing his feet." The thing is, I was totally gobsmacked. At first the prickly nubs in the footbed were a bit distracting, but as I started walking around in them, they became less noticeable, and within the first twenty minutes or so, my feet started to feel energized and soothed. I went outside and swept the deck and did some chicken chores, and I was just in heaven. My legs felt supported and I had this incredible feeling of a whole body support system, starting with the acupressure from the footbed nubs and the lightweight shoe material and the fabulous cushioning. These shoes haven't had enough time to mold to my feet, and I'm already blissed out wearing them. I got mine in the olive green, too. They're earthy and surprisingly cute. My husband hasn't worn a clog in his entire life and walked off wearing them for the first time as if little elves were sitting inside his shoes and if he stepped down too hard, they'd get squished and died. A few minutes later, I saw him disappear down the hill at the back of our property. He can't walk when he gets home, his feet are in that much pain.
# I was looking for something to wear at night while I was on the AIDS/Lifecycle. It's a 545 mile bicycle ride from San Francisco to Los Angeles where we raise money for services to HIV+ patients. The ride involves six nights of camping. It's a huge event and the evenings involve a lot of walking. We are allowed 70lbs of gear, but we have to haul our gear to our tent site every night, so traveling light is important. I wanted one pair of shoes for the week that I could put on after riding my bike all day and they would be comfortable enough to wear all week. I wanted one pair of shoes that wasn't going to get icky if the grass was wet at the campsite in the morning. I wanted one pair of shoes that kept my feet warm while I was walking around the campsite in the evening. These shoes totally fit the bill. After beating up my feet all day in cleats on the bike, they were a welcome respite. They allowed air to flow, but my feet never got cold at night. Dirt just wiped off. If I got some gravel in them, it kicked right back out. These shoes were so comfortable I found myself next to the gear trucks digging through my bag to find them and put them on. I know a lot of athletes use Crocs after their activity to kick around in, and these shoes are the shiznit!
# These are my first Crocs, and lavender seems to run *almost* a size small. I would say the size 8 Crocs in lavender fits closer to 7 than size 8 street shoes. For reference, I wear size 7 in street shoes (Vans, Converse, Franco Sarto boots, Timberland Kinsley boots), size 38 European shoes (Veja), size 8 running shoes (Mizuno Wave Riders), size 8 Vasque Mesa Trek hiking boots. If you can, try them on. When I measured my feet and checked the Crocs size chart, it said I was a size 10, which would have been way too big. Size 8 lavender fit me roomy but comfortable, whether I'm barefoot or wearing thick, fluffy socks, with or without the Crocs shoe strap. They're super comfy!
Those are definitely a bit weird! But, it looks like we’ve built something that works. Very cool.
Looking at More Keywords and Ratings
Let’s see what people have to say about the comfort and fit of crocs that is positive using both our vectorization methods.
find_most_typical(df, 'comfort', 'positive', 'tfidf')
There are 1847 positive reviews that mention: comfort
Most typical reviews are:
# The crocs are very comfortable. I love them.
# The crocs are comfortable, and I love them.
# I love the color and comfort of these crocs!
find_most_typical(df, 'comfort', 'positive', 'count')
There are 1847 positive reviews that mention: comfort
Most typical reviews are:
# The crocs are very comfortable. I love them.
# The crocs are comfortable, and I love them.
# I love them; they are so comfortable to wear.
find_most_typical(df, 'fit', 'positive', 'tfidf')
There are 834 positive reviews that mention: fit
Most typical reviews are:
# Love the color and fit just as comfortably as my other crocs.
# I love these. They are a perfect fit and very comfortable. I love the color as well.
# Very comfortable and great fit. I love them.
find_most_typical(df, 'fit', 'positive', 'count')
There are 834 positive reviews that mention: fit
Most typical reviews are:
# I love them, and they fit great.
# They are a great fit and are comfortable.
# These are so comfortable, and it fits perfect!
What do they say about those aspects that is negative?
find_most_typical(df, 'comfort', 'negative', 'tfidf')
There are 68 negative reviews that mention: comfort
Most typical reviews are:
# I loved Crocs until my shoe size went to 8.5. Now the 9 is too big & the 8 is too small. I can't really comfortably wear either pair.
# I love crocs; they're my favorite. However, for some reason, their sizing has gotten inaccurate. I have an old pair of size 8 women's & it's a perfect comfortable fit, and this time I ordered the same size 8 women's, and it's a little too snug for my comfort, and my toes have less room than usual.
# I love how comfortable this shoe is. However, I wish they had half sizes because I am a 10 1/2 in women and I knew the regular 10 was going to be small, so I got an 11. I didn't like how big it made my feet look. I hope they change their sizing and add half sizes too.
find_most_typical(df, 'comfort', 'negative', 'count')
There are 68 negative reviews that mention: comfort
Most typical reviews are:
# I like how comfortable they are, but they are not true to size because they are too small.
# The sole isn't comfortable for my feet. Standing long in the pair can be painful.
# I bought these for my daughter. She said these are not comfortable like true clogs.
find_most_typical(df, 'fit', 'negative', 'tfidf')
There are 169 negative reviews that mention: fit
Most typical reviews are:
# I have over 20 pairs of crocs, and lately, the last 5 pairs I've purchased have all fit differently. I'm usually a men's 8 & recently bought a red pair of the classic clog. They were entirely too big, which made no sense because I have pink ones the same size that fit perfectly. I purchased a purple pair & decided to size down & get a men's 7 & they were way too small (which also made no sense because I have blue crocs the same size that were a more snug fit). My suggestion is to either make half sizes, or stop with this whole "Roomy Fit" thing that you all are doing. There is zero reason why each pair of crocs should have a different fit. I'll never order crocs online again. I highly recommend just going to the store to make your purchase. The return process is also very strenuous because Crocs does not offer exchanges. So now I have to send them back to the store via UPS, wait for my return to be processed, then wait until I can make my way to a crocs store because the closest store in my area is 36.6 miles away. Ridiculous.
# Well, the crocs do not fit my granddaughter. One is actually a different size than the other. She received another pair of Crocs from her dad, and even though the pair he got her are size 9, and the pair I got her are size 9, the pair he bought her fits and the ones I got her do not. One pair was made in China and one pair was made in Vietnam.
# I have had several pairs of crocs in the past, different styles and colors. Direct from the company. I have been disappointed in the consistency of the sizing. I had a size 10 in the classic style and wanted another pair in a different color. When they arrived, the fit was at least a size larger and wider than my original pair. Then I exchanged for a size 9. This fit better, but now the left shoe is smaller than the right. Not happy.
find_most_typical(df, 'fit', 'negative', 'count')
There are 169 negative reviews that mention: fit
Most typical reviews are:
# I ordered size 11 because they r too big. I thought they fit to size.
# This pair fits a little short.
# One pair of my crocs was a perfect fit, but the other fit was weird.
Conclusion
Well that was fun! After going through and reading the model outputs, it seems that CountVectorizer works the best for solving this problem. Which makes sense considering we are most concerned with finding the most “typical” reviews, and CountVectorizer focuses solely on term frequency to represent documents. Using CountVectorizer seems partial to the selection of shorter reviews, which I would consider an advantage in this space. Quick and succinct is the name of the game here. I really like this idea and may deploy a model based on this concept in the future…