Motivation
Before we get into things, here’s a link to download the dataset if you would like.
Do you ever find yourself pouring over a product’s reviews trying to decide if it’s right for you? I sure do. Many of these times I’ve wished there was a quick summary of the reviews I could read to speed up the decision process. I’ve yet to see any online retailers doing exactly what I’m looking for, so I’ve decided to make my own review summarizer. But, we need some data for training such a tool.
For this project I wanted to use data that was fun, interesting, and maybe even a little controversial… After much thought and deliberation over what product reviews to train a summary generator on, I landed on Crocs. Yes, I’m talking about the clunky rubber footwear my grandmother wears while gardening that some fashionistas would consider an abomination. What’s more fun than that??? Maybe or maybe not to your surprise, I searched the internet for a dataset containing reviews for Crocs to no avail. So, we’re going to have to find our own data. Follow along as I build a webscraper to farm reviews for Crocs Classic Clog, so we can train a review summarizer for the most loved and hated shoes on the planet!
What tools can we use?
There are several Python libraries that are helpful for webscraping:
- Requests: To send HTTP requests to websites.
- Beautiful Soup: For parsing HTML and XML documents.
- Selenium: For scraping dynamic web pages using browser automation.
- Pandas: To manipulate and store scraped data.
In this project, I’ll be using Requests, Beautiful Soup, and Pandas. Selenium isn’t needed because we don’t need to click anything to move through the review pages on Zappos.com as you’ll see later.
Getting Started
Before we start scraping, we need to do some research, meaning that we need to go look around on the internet and assess potential sites for scraping. What sites would have a lot of product reviews for Crocs? The Crocs website itself, Amazon, and Zappos immediately come to mind. After following some initial site evaluation steps outlined here, I decided Zappos.com was the best place to scrape from.
First, we need to figure out how to traverse the pages of reviews on Zappos.com. I went and clicked through the review pages and paid close attention to the URL. I noticed that it explicitly changes with each page. For example, https://www.zappos.com/product/review/7153812/page/1/orderBy/best takes you to the first page, and https://www.zappos.com/product/review/7153812/page/2/orderBy/best takes you to the second page. Easy. To traverse the pages, all we need to do is change a single character in the URL.
Some Code to Download Whole Webpages
I prefer to download whole web pages and extract data from them later. Why? Because companies oftentimes aren’t super happy about you scraping their data, and you have to be careful about how your traffic looks as you surf pages. Manners are important! Extracting data from HTML is a messy process that requires development, and you don’t want to risk having to rerun your scraper because you forgot to write the Beautiful Soup code to extract a product’s rating, for example. A script to traverse and download Zappos review pages is below.
from bs4 import BeautifulSoup
import requests
import random
import time
HEADERS = ({'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36', 'From': 'chandler_underwood@yahoo.com'})
#Download raw HTML
def getdata(url):
r = requests.get(url, headers=HEADERS, timeout=5)
return r.text
#Convert HTML to parsable string
def html_code(url):
htmldata = getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
return (soup)
text = "https://www.zappos.com/product/review/7153812/page/{insert}/orderBy/best"
#Iterate over all possible URLs
for i in range(1, 1000):
#Retrieve HTML
print("Scraping: " + text.format(insert = str(i)))
code = html_code(text.format(insert = str(i)))
#Save file with unique name
file = open("path_to_folder/Zappos_Croc_File_" + str(i) + ".html","w")
file.write(str(code))
file.close()
#Always remember to be polite
time.sleep(random.randint(15,40))
Extracting Data from Webpages
Now that we’ve downloaded the pages of reviews, we need to figure out how to extract the text from the HTML in a useful format. Google Chrome’s page inspect tool is great here as it allows us to click on items within the webpage and find their respective HTML tag names.
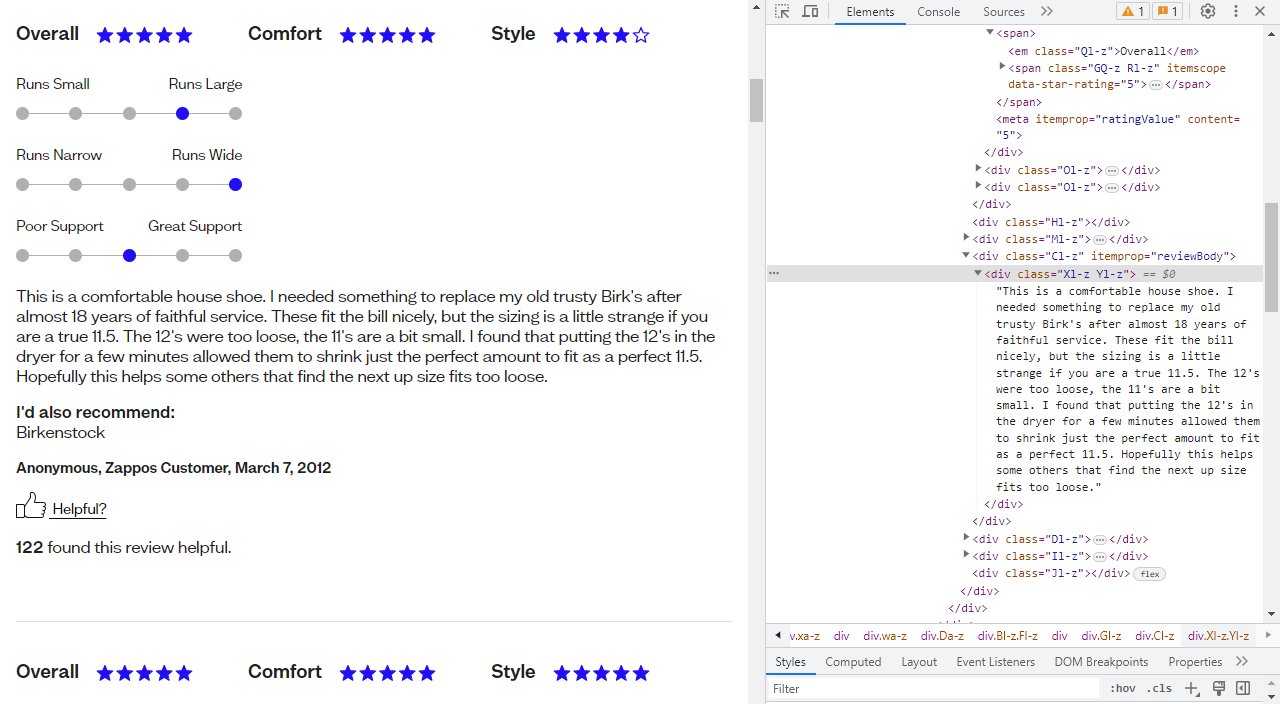
As I clicked on the items I wanted to extract on the webpage, I took note of the tag names associated with them. Beautiful Soup uses these tag names to extract the text we need. Through some trial and error, I ended up with the following function to extract the desired text to make the reviews dataset.
def cus_rev_zappos(soup, b = True):
review_text = []
date = []
rating = []
rating_type = []
rating_return = []
#Extract review
for item in soup.find_all("div", class_="Xl-z Yl-z"):
review_text.append(item.get_text())
#Extract review date
for item in soup.find_all("time"):
date.append(item.get_text())
#Extract product rating
for item in soup.find_all("span", class_="HQ-z"):
rating.append(item.get_text())
#Extract product rating type (Overall, Style, Fit, etc.)
for item in soup.find_all("em", class_="Ql-z"):
rating_type.append(item.get_text())
#We only care about overall product ratings for this project
rating = list(zip(rating[5:], rating_type))
for x in rating:
if x[1] == 'Overall':
rating_return.append(x[0])
return review, date, rating_return
I then iterated over and extracted the text from the downloaded web pages using the following code, and we got a decent amount of data! There are over 9,000 distinct reviews here. Below is a glance at the data.
from tqdm.notebook import tqdm
reviews, ratings, dates = [], [], []
for x in tqdm(range(len(filenames))):
f = open("path_to_folder/" + filenames[x], 'r')
soup = BeautifulSoup(f.read(), 'html.parser')
review, date, rating = cus_rev_zappos(soup)
reviews.extend(review)
ratings.extend(rating)
dates.extend(date)
review_df = pd.DataFrame({'review': reviews, 'date': date, 'rating': ratings})
review_df.to_csv("Zappos_Croc_Reviews_Total.csv")
review_df.head(10)
| review | date | rating | |
|---|---|---|---|
| 0 | !!!!!! E X C E L L E N T!!!!!!!!!! | April 7, 2022 | 5.0 |
| 1 | "They're crocs; people know what crocs are." | April 3, 2021 | 5.0 |
| 2 | - Quick delivery and the product arrived when ... | March 19, 2023 | 5.0 |
| 3 | ...amazing "new" color!! who knew?? love - lov... | July 17, 2022 | 5.0 |
| 4 | 0 complaints from me; this is the 8th pair of ... | June 4, 2021 | 5.0 |
| 5 | 10/10 I ran from the cops in mine, and they ar... | July 2, 2023 | 5.0 |
| 6 | The 11 year old granddaughter loves them!!!!!! | August 7, 2022 | 5.0 |
| 7 | The 11 yr old daughter loves them. | August 7, 2022 | 5.0 |
| 8 | 12M classic clogs made in Vietnam are great, a... | April 25, 2023 | 1.0 |
| 9 | My 13 year old grandson chose this color and l... | March 13, 2023 | 5.0 |
Let’s make a wordcloud to get some understanding of the most popular words in the dataset.
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from os import path
from PIL import Image
import matplotlib.pyplot as plt
# Start with one review:
text = ' '.join(review_df['review'].to_list()).lower()
# Create and generate a word cloud image:
wordcloud = WordCloud(max_words=50, background_color="white").generate(text)
# Display the generated image:
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()

“Croc” and “Love” seem to go together a lot. Why am I not surprised? :) I’m excited to see what I can do with this data in the future! Again, here’s the link to download the dataset if you’d like.